Back in 1871 or 1873, Joseph von Gerlach proposed the Reticular Theory, suggesting that our nervous system is a singular, continuous network rather than a collection of discrete cells. He envisioned it as one immense cell within our nervous system, challenging the notion of distinct cells. This theory, referred to as the reticular theory, presented a revolutionary perspective and sparked considerable debate. Gerlach's idea fundamentally questioned the conventional understanding of the nervous system and left a lasting impact on neurological theories.

In the late 19th century, scientists like Camillo Golgi and Santiago Cajal engaged in a heated debate over the nature of the nervous system. Golgi, using staining techniques, thought the tissue was a continuous network, supporting the reticular theory. On the other hand, Cajal, also employing staining methods, believed it was a collection of distinct cells forming a network. This difference in views led to the neuron doctrine, proposing that the nervous system is made up of discrete cells (neurons) interconnected in a complex network. While Cajal laid the foundation, von Waldeyer-Hartz coined the term "neuron," helping to solidify and formalize the neuron doctrine. This collaboration underscores how different perspectives and contributions played a vital role in shaping our understanding of the nervous system's structure.
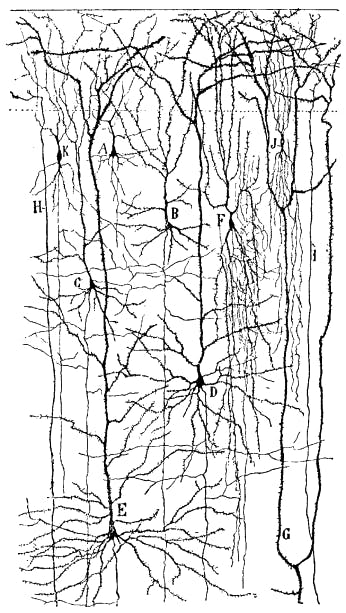
Surprisingly, the resolution of this debate occurred much later, in 1950, and it wasn't due to advancements in biology but rather a breakthrough in a different field—electron microscopy. With the introduction of electron microscopy, researchers could observe the nervous system at a finer scale. Examining it under the microscope revealed a gap between neurons, negating the idea of a single cell and confirming it to be a network of cells. These connections, now identified as synapses, became evident. This pivotal moment in the debate occurred with the improved clarity provided by electron microscopy, settling the long-standing disagreement.
In 1943, there was a growing fascination with unraveling the mysteries of the human brain and creating a computational or mathematical model to mimic its functions. Enter McCulloch and Pitts, an unusual duo consisting of a neuroscientist and a logician, not computer scientists. Together, they crafted a remarkably simplified model that mirrored how our brains process information. Imagine deciding whether to go for a movie:
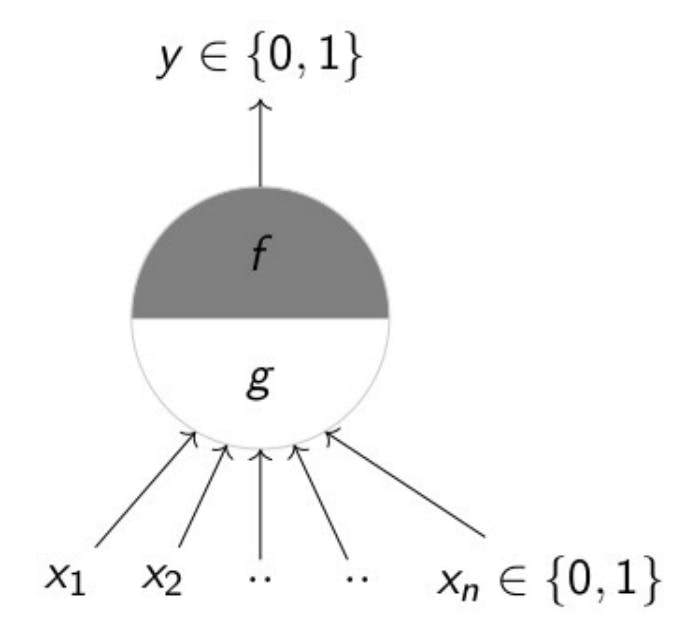
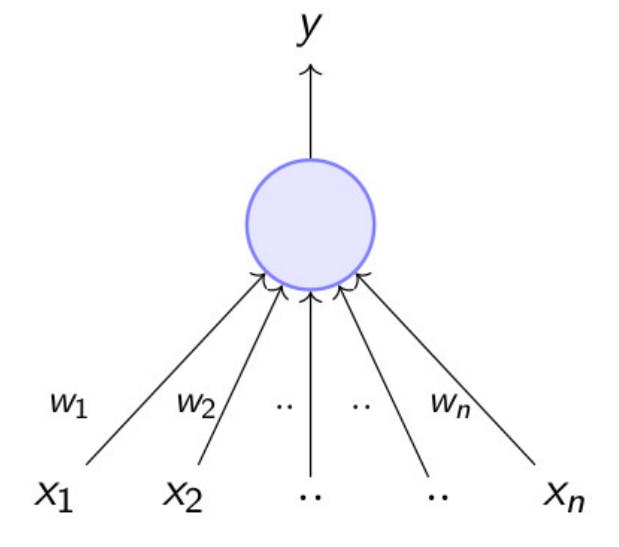
you'd consider factors like upcoming exams (let's call it X1), the weather, possible traffic, and the popularity of the movie. McCulloch and Pitts proposed that, similar to this decision-making process, an artificial neuron could take inputs from various sources, process them through a function, and arrive at a binary decision – in this case, a simple yes or no about going to the movies. This marked the birth of an artificial neuron, not a biological one, but a foundational concept in the journey toward understanding and replicating the brain's computational abilities. Around 1956, the term "artificial intelligence" was officially coined during a conference. Within a year or two, Frank Rosenberg introduced the Perceptron model, envisioning it as an artificial neuron for computations. However, what stands out is his statement that the Perceptron could potentially learn, make decisions, and translate languages. The specificity of language translation is intriguing, but it makes sense when connected to the historical context of the Cold War. During this period, there was a heightened interest in language translation driven by espionage and the need to understand rivals' activities. Research in this area often received funding from agencies with military or defense interests. The Perceptron's potential for language translation aligned with the geopolitical landscape of the time.
In 1957 or 1958, an article in the New York Times referred to the Perceptron as the embryo of an electronic computer.

“The embryo of an electronic computer that the Navy expects will be able to walk, talk, see, write, reproduce itself and be conscious of its existence” - New York Times
The Navy, at the time, envisioned this embryonic technology evolving into a machine capable of walking, talking, seeing, writing, reproducing itself, and even being conscious of its existence. It's fascinating to note that discussions about the potential of AI, including its transformative impact and promises, date back to this era. Fast forward to the present, and we're amidst a surge in AI hype, with the concern about the job displacement and the idea of AI agents potentially taking over.However, what's crucial to recognize is that these concerns and promises are not new; they have been part of the AI discourse since the late 1950s. Over the past 8 to 10 years, the field of artificial intelligence (AI), particularly in the context of deep learning, has witnessed significant advancements. Deep learning primarily revolves around the concept of neural networks—systems composed of interconnected artificial neurons organized in layers, working together to achieve specific objectives.
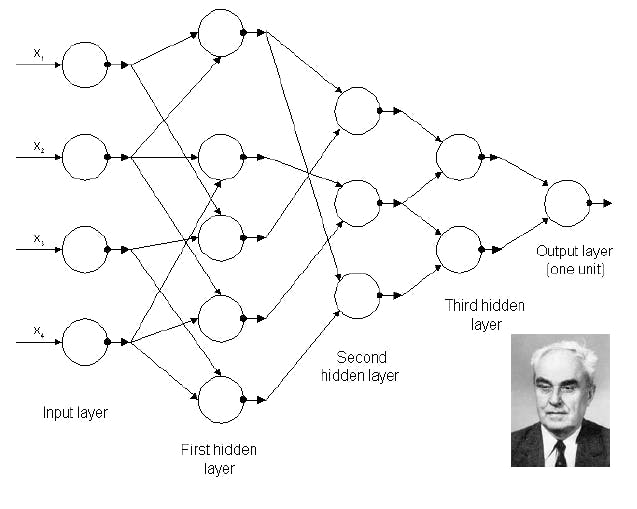
This approach, though extensively discussed in recent years, is not entirely novel. In fact, the roots of deep learning trace back to the late 1960s when researchers like Marvin Minsky were exploring architectures resembling modern deep neural networks. Minsky is often regarded as one of the pioneers of contemporary deep learning. Looking back further, from 1943 to 1968, AI experienced a period of enthusiastic exploration, commonly referred to as the "springtime for AI." During this era, there was widespread interest, substantial government funding, and high expectations regarding the potential applications of AI in diverse fields such as healthcare and defense. In essence, the trajectory of AI, especially within the domain of deep learning, has seen a rich history marked by foundational work in the mid-20th century and a resurgence of interest and advancements in recent years.
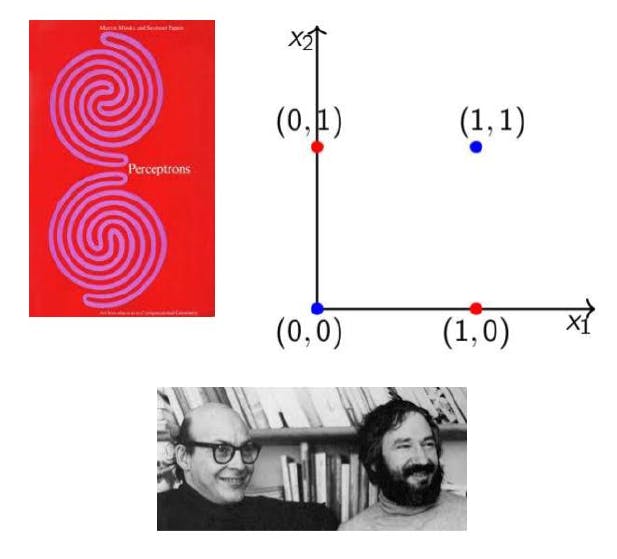
Around 1969, Marvin Minsky and Seymour Papert published a noteworthy paper highlighting certain limitations of the Perceptron model, a fundamental concept in artificial neural networks. The paper pointed out that Perceptrons faced challenges in handling even relatively simple functions, such as the XOR function. The inability of a single Perceptron to model these functions led to a period of severe criticism for AI.
This criticism, coupled with the perception that Perceptrons were incapable of handling complex tasks, contributed to a decline in interest and a reduction in government funding for AI research. This phase, known as the "AI winter of connectionism," persisted from 1969 to 1986. During this period, there was a lack of enthusiasm for connectionist AI, which includes neural networks—a paradigm that contrasts with symbolic AI. Despite Minsky and Papert's acknowledgment that a multi-layer network of Perceptrons could overcome these limitations, the emphasis on the initial critique fueled a prolonged period of reduced interest in AI advancements.
In 1986, the introduction of the Backpropagation algorithm marked a crucial advancement in the realm of artificial neural networks. Rumelhart and others played a key role in popularizing this algorithm, which allowed for the training of deep neural networks. Although not entirely their discovery,as Backpropagation had roots in other fields like systems analysis, it was in 1986 that its potential for deep neural networks was prominently recognized. This algorithm, still widely employed today, became fundamental for training neural networks, showcasing the enduring impact of a breakthrough made nearly 30 years ago.
Simultaneously, the use of Backpropagation coincided with the application of gradient descent, a technique dating back to 1847 when Cauchy employed it to calculate the orbits of celestial bodies. Over the years, gradient descent found diverse applications, from discovering patterns like cats in videos to medical imaging for identifying features like cancer in X-rays. The conjunction of Backpropagation and gradient descent exemplifies how seemingly antiquated methods have persisted and evolved, remaining relevant even in the context of cutting-edge technologies like deep learning.

In 1989, the Universal Approximation Theorem added another layer to the narrative. This theorem highlighted the capability of deep neural networks to model a wide range of continuous functions with precision. In essence, it suggested that if a decision-making process is a highly complex function of inputs, a neural network can learn and approximate this function. This theorem, while emphasizing the versatility of deep neural networks, also introduced caveats and considerations. Despite these foundational discoveries, the late 1980s and early 1990s witnessed challenges in applying deep neural networks to real-world problems due to limitations in computational power, data availability, and issues with training deep networks. This period, characterized by highs and lows, set the stage for further developments leading up to the eventual resurgence of interest in deep learning around 2006.